
For the next six chapters, we will explore how modern technology has evolved, is built, is maintained and is upgraded. Digital literacy is one of the most essential attributes of an In The Loop leader. Build your technical environment well and you’ll gain increasing leverage. Build it poorly and the opposite will be true. Digital capabilities such as cloud computing, machine learning, AI, big data, blockchain and emerging mobile and IoT solutions (such as 5G) open up powerful generative and adaptive opportunities for the enterprise. But they can’t happen without digitally literate leaders. Not just the technical leaders. In the fit systems enterprise, all senior executives need to know enough about modern technology requirements to debate priorities and support technical leaders in resource decisions and setting time-based milestones.
Our exploration starts with reactive systems and microservices architecture. Just as human systems are best organized into clusters of small, loosely coupled work groups, so too in technical systems. When a technical system is built modularly as a set of microservices, each service can be managed and improved more easily. A technical domain team assigned to a service can adapt and optimize the service without dealing with the complicated interdependencies found in a monolith. The fit systems enterprise’s basic organization design building block — the domain team — is well suited for systems built via microservices architecture.
Wherever data volume, variety or velocity are high, where concurrent processing is needed and where computations need to be broken down into steps, microservices are not enough. These microservices must also be reactive. Reactive microservices architecture is a specific type of microservices architecture. The reactive property enables a service to be elastic (compute resources can scale up and down on the cloud), resilient (if a node fails, it can self-heal) and responsive (high availability / low latency). The key to reactive microservices is asynchronous message passing between services.
Background
If your company is an early stage startup, you may well have built your technical systems monolithically. You might have concluded that until proof of product / market fit, it didn’t make sense to invest the extra time and effort required to build microservices. There is an entry cost to microservices architecture. It adds complexity to build multiple services and service instances, and then manage the interactions between them. Development complexity increases further if you need microservices to be reactive. Reactive microservices architecture is typically deployed once a company has grown to the point where multiple technical domain teams are in place.
On the other end of the scaling spectrum, if yours is a big established enterprise, your technical systems may still be monolithic. They were built at a time when there was no alternative. There may be one very big monolith — for instance, one relational database for the entire enterprise — or perhaps your systems are broken into multiple smaller monoliths, following the principles of Services Oriented Architecture (SOA).
A monolith is known by its scope. If the services it encompasses are beyond the capacity of any single senior systems architect or expert developer to deeply understand, it is a monolith. In the monolith, components are tightly coupled, with synchronous message passing between them. Any upgrade to a component requires an update to the entire system. Since dependencies are complex, upgrades must be planned and reviewed carefully up front — a waterfall approach. Because of this, supporting the monolith tends to require a monolithic organization structure.
Whether big and established — or smaller but growing — it may be time for your company to shift to reactive microservices architecture.
For the rising startup, you need to increase adaptability, scalability and speed (too many startups delay the shift to microservices at their peril, increasing the technical debt, making it harder and harder to manage over time). For the large, established enterprise, perhaps you’ve realized you can’t process the volume and variety of data, at the velocity you need, to compete. Maybe your competitors use machine learning to continuously update pricing based on dynamic assessments of competitive prices. Or perhaps they use social media sentiment data to track brand health. Maybe they have tapped machine learning to build robotic process automation solutions that make them massively more efficient than you. You need to get in the game. But these capabilities require a new type of technical infrastructure.
Over time, reactive microservices architected systems simply perform better than monoliths:
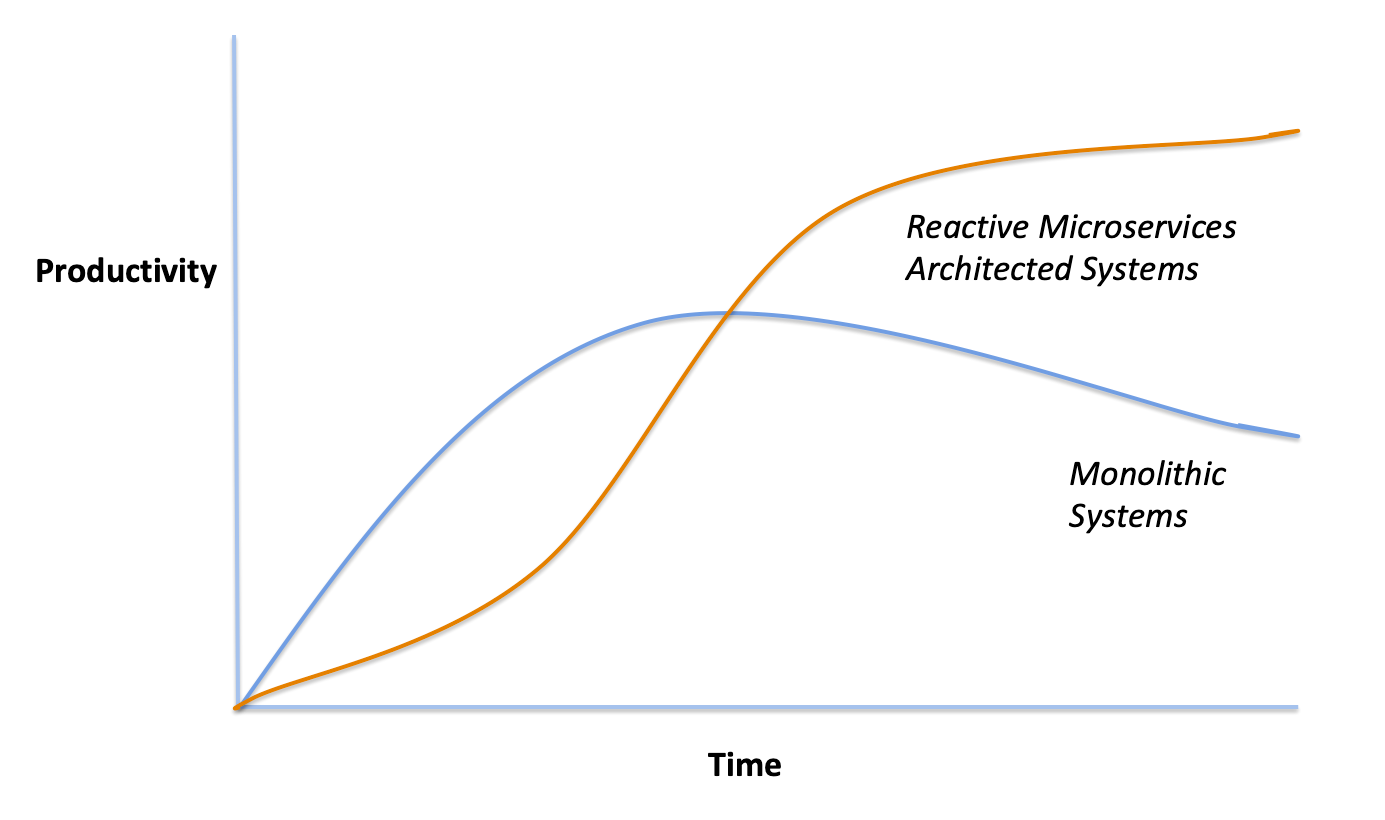
Refactoring the monolith is a big investment, and the reward will take time to be achieved. It takes an In The Loop leader to understand that the short term sacrifice will be eventually be rewarded in long term acceleration.
The Monolith: Attributes, Benefits and Constraints
Not all monoliths are the same. Some enterprises feature solitary monoliths; others feature multiple ones. are Some monoliths have been thoughtfully built. Others are irredeemable wastelands.
There are use case scenarios in which a monolith could be the right technical solution for you. If your team is small and your application unproven, a small monolith might be the best way to go — simpler to build and maintain until you prove it. Or if your application is so proven and straightforward that it is unlikely to require change in the future, or if you need high data consistency and the data throughput demands of your application are not excessive, a monolith might be just fine.
But if the problem domain is evolving, or you plan to upgrade the software in stages, or the solutions are not obvious, or the rate of change the domain is experiencing is high, or its data demands are rising — these types of problems are not well served by a monolith. You can’t establish your requirements up front when solutions are fuzzy. You need to experiment — test ideas. Experimentation needs to be easy. Experiments are easier if you attack the problem with microservices architecture.
In the large enterprise whose technical stack was formed in the eighties and nineties, its architects probably followed Services Oriented Architecture principles. This is the precursor to microservices architecture. Perhaps they built coarsely grained services, and managed them via web services, deployed in an application server. This probably required use of an Enterprise Service Bus (ESB) to connect all services and systems.The ESB often holds business logic, and manages communications between components.
Like this:
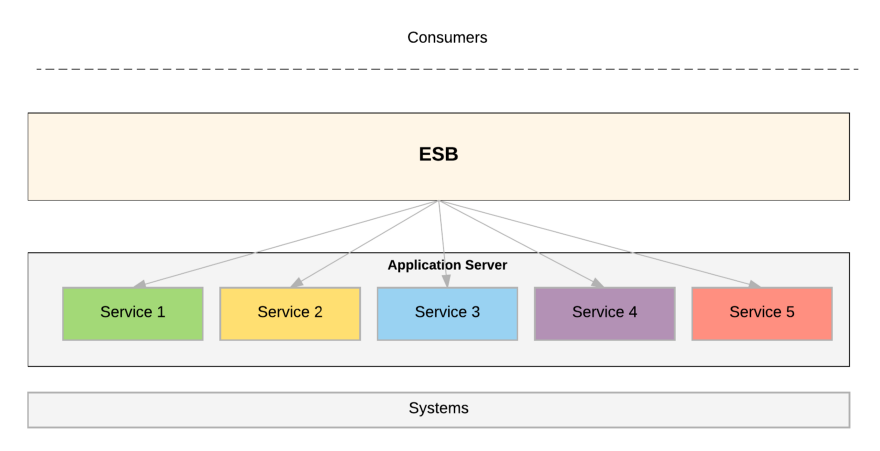
Here the ESB handles message routing, the execution of business logic and the orchestration of services. It runs as a single monolithic runtime. Since web service technologies such as SOAP, WS Security, and WSDLs are complex and are not built to support an API ecosystem (such as for self-servicing), an API gateway might be built on top of the ESB, like this:
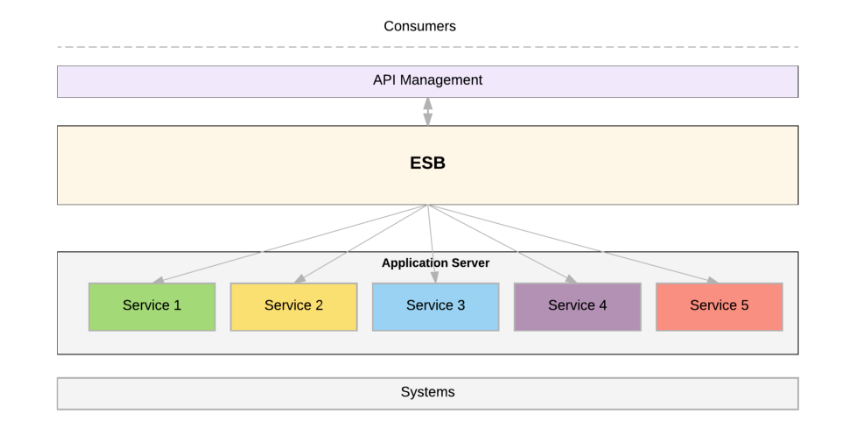
At scale, the ESB becomes problematic. Since ESBs tend to have significant business logic built into them, some have called the ESB an “Egregious Spaghetti Box”. In some enterprises, committees of people are needed to lay down standards for touching the ESB.
In many monoliths, data sits in a big relational database. You might hear someone say, “Our company standard is Oracle” or “Our company standard is DB2.” Since the data is separate from the service and is connected to the service via synchronous message passing methods, processing times are longer and blocking routines (which make things even slower) are common.
Monoliths have some advantages:
- Simpler to build
- May be easier to work within a single codebase than with multiple codebases up to a certain level of scale
- Can work for low variation problem patterns with limited data demands that are unlikely to change over time
- Can work when strong data consistency is required
Disadvantages:
- Have to upgrade the entire monolith every time you change it
- If some components in the monolith require rapid rates of change and others don’t, the entire monolith must change at the rate of the most rapidly changing component
- When lots of independent services are combined in one monolith, any point of failure can bring down the entire system
- Much harder to support continuous delivery if in a monolith
- Difficult to scale
- Difficult to maintain and upgrade
- Monolithic systems force monolithic organizations: multiple teams need to synchronize their work
- Lots of cognitive load to understand all the dependencies inside: makes the enterprise more at the mercy of legacy “experts” who know the intricacies of the monolith
Business Benefits of Reactive Microservices
So why put the extra work into refactoring your monolith into microservices and making your systems reactive? In the digital era, where change is constant, reactive microservices deliver the adaptability, efficiency, speed and organizational decentralization required to win.
Reactive microservices:
- Make it easier to build and maintain applications
- Make it easier to evolve and scale applications
- Exhibit lower latency than overstressed legacy systems (when properly designed)
- Deliver improved developer productivity
- Are more efficient in the use of computing resources
- Have reduced failure risk
- Enable each service to be built with whatever technology is required to meet its needs; doesn’t need to be the same (though if there is too much diversity in service technologies it makes continuous deployment toolchains more difficult to build and maintain)
- Enable fast data applications such as streaming and real-time machine learning
- Work well with a self-organized, domain-based team structure
The result is an enterprise that can build faster, adapt faster, process faster, employ more advanced technology, reduce failure risk, run more efficiently and attract better developers (because microservices are more fun to build and maintain).
Reactive Microservices Architecture: Attributes and Constraints
Architecture is the shared understanding expert developers have of the system’s design. It is inherently a social concept, because it’s only valuable if all key members of the team understand it. A sound architecture delivers the intended user experience, free from defect. These are its visible attributes. But it also exhibits elegance under the hood. Well designed architecture yields high quality infrastructure. This is the basis for the long-term health and scalability of your systems. Done well, your technical infrastructure will increase your capacity to launch more features, faster and faster. In a world of continuous change, this a point of real competitive advantage.
Microservices-based architecture starts with the isolation of services. Each service is of a size that can be managed by a small team, with a shared understanding of what’s in it. In some domains, the encapsulation boundary may need to encompass multiple services. In fact, if something you are doing needs to routinely touch more than four services, it may be best to encapsulate them together into one larger service. This works when the services frequently interact with each other, and when the rates of change required of these services are similar.
In microservices architectures, the encapsulation decision follows the single responsibility principle, under which a boundary is set consistent with a subdomain’s bounded context. This follows the principles of domain driven design as articulated by Eric Evans in “Domain Driven Design: Tackling Complexity in the Heart of Software¹.” The service boundary correlates to a business requirement, not a technical function. The key is to find the sweet spot where the advantage of microservices can be leveraged without creating a new type of complexity.
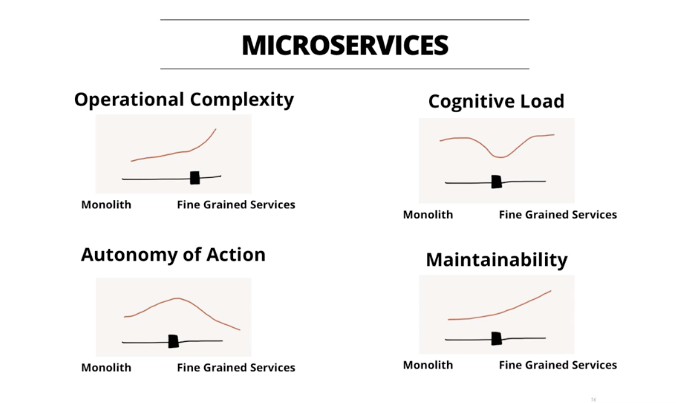
In Chapter 15 I referenced a presentation by Ryan Murray and John Napier from ThoughtWorks in which they proposed a way to think about the level of service decomposition. They see four key factors:
- Operational complexity
- Autonomy of action
- Cognitive load
- Maintainability
In deciding the atomicity of a service, it’s important to balance these four factors. The authors argued that each of these factors exhibits different optimal points. Like this:
Each service is the responsibility of a technical domain team. In the fit systems enterprise, cross-functional domain teams own the development and continuous improvement of the microservices to which they are assigned. They pursue continuous delivery by following the disciplined agile delivery method. By owning the optimization of a microservice at every development step and from top of stack to bottom, a technical domain team is able to own business outcome responsibility. The team is well positioned to respond to change, and to continuously adapt technology to meet evolving needs in every domain.
With microservices, each service owns its own data and its own persistence. Unlike the monolithic model, where business logic is likely to reside in an ESB, in microservices the end points are smart and the pipes are dumb. There is still orchestration, but the orchestration layer is thin. Choice of persistence, and the languages used for its software, can be unique to each service. Since it is isolated, each service is independently scalable and resistant to failure. It can be replicated easily to allow for concurrent processing. Services interact with each other asynchronously via APIs. Services integrate together to form a system.
With microservices, you explicitly design for failure. Since services are easily replicated, a failing service can be taken down without the system going down. System monitoring is critical in microservices. Netflix has built something they call the Chaos Monkey that roams through its distributed systems trying to make services fail. In that way it discovers points of brittleness so that teams can continuously increase system resilience. In a distributed system you assume things will break, and design accordingly.
A key issue in microservices is consistency. Because microservices architecture enables you to process concurrently in time and independently in space, the system’s understanding of “truth” is always evolving. In microservices, architects embrace the idea of “eventual consistency” wherever the business logic allows for it. This means that the answer given by the system at any given time is “roughly right,” and is able to be updated later as more data streams in.
At operation time, you need to be able to monitor the interactions of autonomous services. Since domain teams are increasingly focused on separate services, you need to make sure the communications between services remain healthy. This requires monitoring and support so you can catch runtime issues. Under certain circumstances, if a service fails and failure has not been handled explicitly in system design, it could create a rolling failure. That’s why monitoring is so important. Every entity must be traceable as it enters the pipeline, goes through transformations and comes back out.
It usually makes sense to atomize microservices as you scale. As the services are split in two, the domain teams split as well; two teams will form where one used to suffice.
Reactive microservices have emerged to better address today’s world of spiky data and data-rich, interactive user experiences. As described in the Reactive Manifesto², reactive microservices are:
- Responsive (responds in a timely manner; always on)
- Resilient (can self-heal)
- Elastic (can quickly scale up and down based on need)
- Message driven (asynchronous message passing between isolated, loosely coupled, location-transparent components)
As Jonas Boner articulated in his outstanding book, “Reactive Microservices Architecture: Design Principles for Distributed Systems³”, they require that you:
- Follow the principle “do one thing, and one thing well” in defining service boundaries
- Isolate the services
- Ensure services act autonomously
- Embrace asynchronous message passing
- Stay mobile, but addressable
- Design for the required level of consistency
In reactive systems, these principles apply at all levels of scale — enabling the enterprise to remain agile and adaptable no matter what the data volume, variety or velocity requirements. These days, networks are fast, disks are cheap and fast, RAM is cheap and multi-core processors are cheap. All of these factors favor the reactive microservices architecture approach.
Requirement #1: Do One Thing And One Thing Well
When you follow the Single Responsibility Principle in service development, programs have a single purpose. You build the service so that a class or component only has one reason to change. This ensures the jobs to be done in a service don’t become too complicated. It makes everything more extensible, maintainable, scalable and resilient.
Requirement #2: Isolate Services
Isolation is critical to self-healing, scalability, continuous delivery and efficiency. It requires communication boundaries that are connected asynchronously, which allows decoupling in time (which enables concurrent processing) and space (which enables distribution and mobility). To enable systems distribution and concurrent processing, developers leverage virtualization and containerization. Docker, Linux and Unikernels offer these.
One of the key benefits of isolation is the isolation of failure. Just as boats have bulkheads to contain and manage failure without water flowing into the entire hull, so too with isolation. If one replicated service fails, its duplicate can be immediately initiated. With isolation, changes to a service can be rolled out incrementally without any dependency on other services. You can debug and test service by service, without affecting the entire system.
Requirement #3: Act Autonomously
Isolation ensures autonomy. The information necessary to fix a failure or resolve a conflict is available within the service. The service can publish its API and promise its behavior. This makes service orchestration more flexible, and supports workflow management and collaboration. The cost is that APIs need to be well thought through. They need to be composable and precisely defined. Communication and consensus routines are challenging problems that must be thoughtfully addressed. REST-style APIs are the most well known, but it should be noted these can often be synchronous; it cannot be used in reactive microservices if it is synchronous.
Requirement #4: Message Asynchronously
Asynchronous message passing ensures resiliency, scalability and more efficient use of computing resources. It enables fast data capabilities, such as streaming data. It is a key enabling feature of the Actor model, developed to enable the efficient scaling (up and down) of compute resources.
Because every service is isolated and autonomous, one service can’t ping the persistent storage of another service directly. It must request access via an API. If a service needs to know the state of another service, it must send in a request. The targeted service will then determine whether it will reply. If it does, it will send only facts (immutable data). It won’t expose its mutable state directly to any other service.
To support these communication patterns, asynchronous message passing is required. Inside of a service, logic is executed synchronously. But between services, communications are asynchronous. This ensures decoupling in time (allowing concurrent processing) and space (allowing mobility and distribution).
Using asynchronous message delivery means that you must deal with uncertainty. Vaughn Vernon, in his blog “Modeling Uncertainty with Reactive DDD”, says it this way:
“With microservices and reactive comes uncertainty, starting with uncertainty about what order events might be delivered in, and if an event has been received more than once, or not at all. Even if you’re using a messaging system like Kafka, if you think you’re going to consume them in sequential order, you’re fooling yourself. If there is any possibility of any message being out of order, you have to plan for all of them being out of order⁴.”
As a message enters a service, it is stored as a command or an event. Stored in the order they are received, these message entries become a transaction log. The log is a critical part of the system, because it enables querying and auditing. This in turn enables the debugging of problems and failure recovery. A persistent event bus allows for less coupling. Kafka is especially effective for message processing.
Unlike the monolith, where one database may be used for all its applications, the specific database used by a service for its persistent storage can be customized according to need. It might be an RDBMS, NoSQL, EventLog or Time-Series format. Renowned software architect Martin Fowler calls this “polyglot persistence”: each microservice can feature its own database, tailored to the service’s unique need.
Jonas Bonér, the author of “Reactive Microservices Architecture,” shows how messages enter a service, initiate a job and are added to an event log:
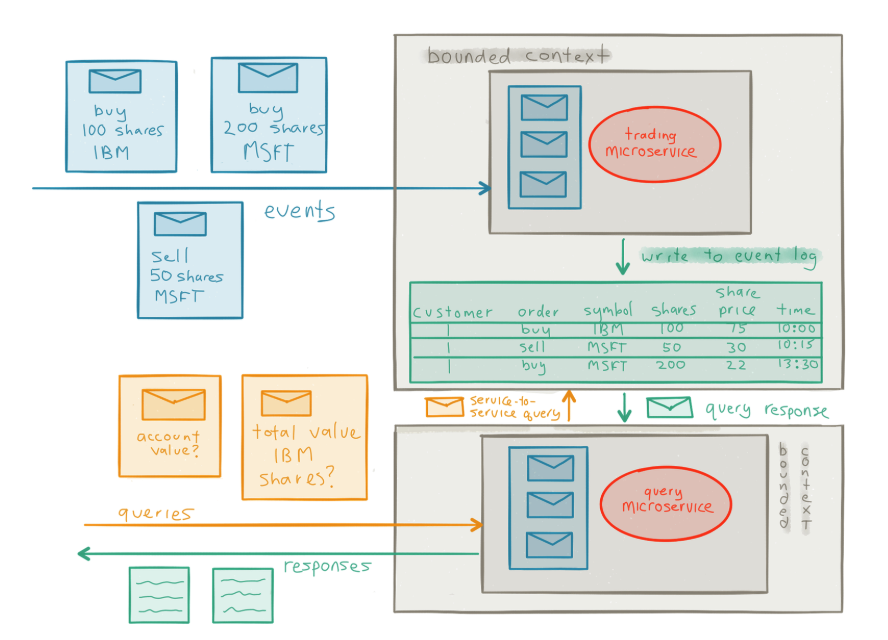
Because messages are asynchronous, work can proceed on different steps in a process without waiting for other steps. If a service wants to execute a task in collaboration with another service but finds the other service already occupied, it can switch gears and execute other work while it awaits the availability of the other service. By this means, no business logic is held hostage to another service. Because it minimizes the problem of contention, asynchronous message passing enables massively more cost-efficient and speedier processing. The focus turns to application communications and the interaction between different services to ensure the right data flows to the right services to deliver the right user experience.
Requirement #5: Stay Mobile But Addressable
Reactive systems are elastic. That means they can scale up and down as required to support the processing load of the system. This requires compute resources to be made accessible when needed. If a service experiences a burst of demand, it must be able to, at runtime, access multiple nodes or cores without changing the code. This in turn requires that the service is addressable, so that its location is transparent. These addresses are virtual. They define one stateful service, even though they may represent many runtime instances. They must remain stable within the service, independent of the number or location of the machines the services happen to be running on.
This mobile, addressable attribute of reactive microservices enables elasticity and resiliency because new instances can be quickly spun up or shut down. Load balancing becomes more efficient. While every request for a service must come into one machine, the requested state change is made available to all passive instances of the service so as to enable failover capability. Using this approach, a service can be moved from one location to another, to increase resource efficiency.
Requirement #6: Design for the Required Level of Consistency
As time marches on nanosecond by nanosecond, the state of things is in constant flux. The reporting of any state is out of date the moment it is reported. Information is always in the past. In some applications, strong consistency is required. This is true in many financial transactions, such as in the recording of a stock price or the daily closing prices of every stock offered on NASDAQ. But in most data driven applications, eventual consistency is adequate.
Wherever strong consistency is required, coordination and consensus is necessary across the whole distributed system. This is expensive, usually requires high latency and makes it harder to manage throughput. Because of the requirements of coordination and consistency, each service needs to wait for system-wide consensus. Monoliths tend to be tied to a single SQL database, and offer strong consistency. With reactive microservices, wherever eventual consistency is possible, it is preferable.
An example of eventual consistency is the hotel bill. Your bill might initially not show a charge for that bottle of beer you took out of the minibar. Then later the bill will be updated. That’s eventual consistency. Wherever facts frequently change and it’s acceptable to be “roughly right”, eventual consistency is the preferred approach. Only build for strong consistency when you absolutely have to.
Summary
Reactive systems built via microservices architecture are a central feature of the fit systems enterprise. If you build high integrity systems following reactive systems, you will gain much digital leverage. You will keep ahead of technical debt through continuous incremental improvements. You will “divide and conquer,” knowing that each domain team is focused on doing just one thing and one thing well. Like Legos, each domain is a building block in a comprehensive structure that fulfills your company purpose. You will be able to leverage the latest technology to do great things in your business.
To view all chapters go here.
If you would like more CEO insights into scaling your revenue engine and building a high-growth tech company, please visit us at CEOQuest.com, and follow us on LinkedIn, Twitter, and YouTube.
Notes
- Evans, Eric. Domain-Driven Design: Tackling Complexity in the Heart of Software. Boston, MA: Addison-Wesley, 2014.
- “The Reactive Manifesto.” The Reactive Manifesto, n.d. https://www.reactivemanifesto.org/.
- Bonér, Jonas. Reactive Microservices Architecture: Design Principles for Distributed Systems. Sebastopol, CA: O’Reilly Media, 2016.
- Vernon, Vaughn. “Modeling Uncertainty with Reactive DDD.” InfoQ. InfoQ, September 29, 2018. https://www.infoq.com/articles/modeling-uncertainty-reactive-ddd.