
The numbers stagger. Every day, 2.5 quintillion bytes of data are created worldwide. In the past two years, ninety percent of the data that now exists in the world was created. Google processes 40,000 searches per second. Walmart processes 1 million transactions per hour. For eBay 5 million metric data points stream in per second. On Facebook, 350 million new photos a day are uploaded.
Eminent data scientist Ash Damle describes a series of emerging shifts powered by data: “We’re seeing the shift from humans driving cars to cars driving humans. From humans going to shops to shops going to humans. From waiting for our favorite show to our favorite show waiting for us. All of these have been enabled by real time big data transformation¹.” As the cost of storage and computing decline and networks become ever faster and more reliable, data’s big bang expands faster and faster throughout the universe.
It should be noted at the outset that any consideration of data in the enterprise must address data access issues such as privacy, cybersecurity and permissions. We will turn to these issues in Chapter 29 — Trust.
Data sparks analyses and actions ranging from simple to complex. A data state change may invoke a simple system change. Or it may be used to describe, predict or prescribe. It might even invoke an intelligent automated response, such as with autonomous driving. As discussed in Chapter 16, data outputs can be:
- Deterministic (a trigger initiates an automated cause-effect transformation inside a machine — such as adding to an event log or a call to a web page)
- Descriptive (business dashboards — KPIs)
- Diagnostic (ad hoc search, query tools such as Hadoop, Presto, Impala — exploring data to find intelligence; leads to statistical models and analysis reporting)
- Predictive (modeling, data science, machine learning — apply statistical techniques to train models that predict based on past behavior, using tools such as Apache Spark)
- Prescriptive (recommendations from machine learning, artificial intelligence, deep learning — enables you to derive increased structure out of loosely structured data — i.e. image recognition and natural language processing — using tools such as Google’s TensorFlow)
- Cognitive (acts automatically based on rules, leveraging machine learning, artificial intelligence, deep learning — such as is used in robotic process automation)
Data needs and uses are diverse. But the effective management of that data comes down to achieving three objectives:
- Deliver every domain team in the enterprise the actionable data and analysis it needs (in the form, frequency and speed required) to perform its job
- Deliver every technical system the data it needs (in the form, frequency and speed required) to perform its job
- Do so at the lowest possible cost
Overview
To achieve the three objectives noted above, a data system must:
- Ensure data is structured with known schemas
- Ensure changes to data can be tracked
- Ensure data is persisted in a task-appropriate and secure database, available for search and aggregation
- Ensure users can efficiently access, process and use the data
- Ensure efficient and secure use of compute resources
- Ensure capacity to monitor performance and fix problems
In today’s world, there are fewer and fewer scenarios where it makes sense to manage data on premises. For most use cases, cloud-based solution architecture is simply superior. The cloud delivers elastic compute, resulting in order-of-magnitude savings as compared to on premises computing. It is also more secure. No enterprise can credibly claim its security protocols exceed those of AWS, Google Cloud or Microsoft Azure. Cloud providers have also built up an array of tools that help with orchestration, monitoring and management of cloud-based systems.
So what is the general solution architecture for a big data system in the fit systems enterprise? It looks like this:
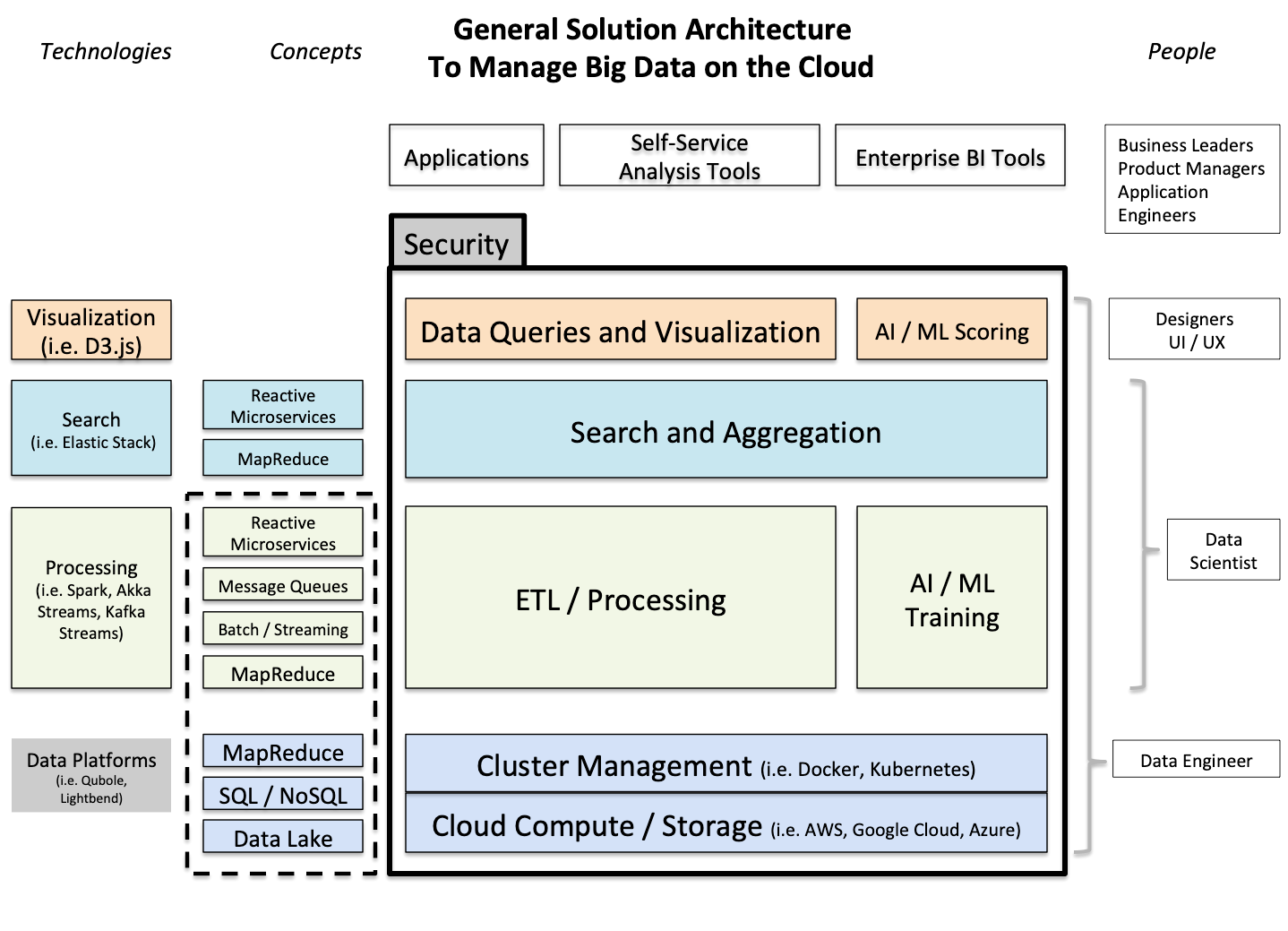
In this general solution architecture, real time processing of large datasets can be supported at scale. Extract / Transform / Load (ETL) processes ensure effective capture, ingestion, preparation, cleansing, application of business logic, analysis and egress of data and their results. There is also real time search and aggregation, with query processing, an aggregation pipeline (MapReduce) and capacity to push the result. The data query and visualization layer ensures that queries can be composed and invoked. The entire system has strong security, and data platforms provide robust monitoring capability.
Data System Requirement #1: Data is Structured with Known Schemas
Data is useless without a schema. A database schema defines the database. Database designers design a data schema to meet business needs. Programmers use the data schema to understand, access and update a database. A database schema defines the organization of data, the relationships between data elements and the constraints to be applied. It includes the physical database schema, addressing the form of storage (files, indices, etc.) and how it will be stored; and a logical database schema, which defines its logical constraints — such as its integrity constraints, tables and views.
With SQL databases, the schema is enforced by a relational database management system on Write. With NoSQL databases, the schema is partially defined (semi-structured data) on Write, providing enough definition for it to be accessible, but is fully enforced on Read (which requires that the application-relevant schema be built into application code or defined through metadata).
Data that is schemaless is useless.
Data System Requirement #2: Ensure Changes to Data can be Tracked
Everything you do must be trackable.
In the old days, when monoliths predominated, there was just one source of truth. Database administrators were able to centrally track schema changes, update ETL pipelines and manage other data services as necessary. As the enterprise moved beyond monolithic systems, a problem arose. Now there is no longer one centralized source of truth. Data is distributed across many microservices. For instance, to know everything about a user, you might need to query the user account service database, the transaction service database, the CRM system and other application-specific databases residing in separate microservices.
To track change in a microservices architecture based system, event logs are required. These event logs must be immutable, capturing unchangeable facts. When a data state change occurs, a microservice writes a log entry to record the intended change. Every change in data state and every action taken must be captured. This enables all fundamental data operations, such as querying, versioning, failure detection and rollback capability.
In the pattern called Change Data Capture, the service’s state is modified while a separate process captures the change and produces the event. By making change notification a separate process from the change in the service state itself, data consistency is maintained. This pattern is particularly relevant for supporting CRUD (Create, Read, Update, Delete) operations.
Since there is no one single view of the data and in a microservices architecture you must go through an API to request data from a database, multi-database queries become more challenging. The Change Data Capture pattern was built to ensure each change was captured and logged in an event log. Kafka was designed for this purpose in mind.
For example, in a Kafka message bus, the receipt, processing and final disposition of every message is recorded in an event log. If a message is not properly received, it may be sent again and again until it is received properly — or until a timeout signals there is a system failure. All of these events are captured in the log. The event log is a critical building block in a resilient technical system.
Now you have an event log of all of your data. Despite data sitting in separate microservices, the event log provides you a unified view of all data including all changes over time. Change Data Capture is vital to data management in a reactive microservices architecture environment.
Data System Requirement #3: Ensure Persistence in a Searchable Database
You can’t manage what you can’t find. A schema defines the structure of your data in a way that the database can understand, making the data searchable.
The range of use cases for data is wide. Data may need to be processed in real time to maintain live operations. Real time data processing can be as simple as a CRUD operation dealing with structured data, or process more complex business logic on structured data, or conduct an analysis on semi-structured data. The database you use in one microservice to conduct one type of data processing is likely to be different than the database you would use for other purposes. Not all databases are the same. The database you choose must be driven by the job you need to do.
Martin Fowler and Pramod Sadalage, in a presentation “Polyglot Persistence,” argue that the day of a single database for all enterprise applications is over. The enterprise can and should build the right database for every need. In their presentation, they show the following example of a retailer’s e-commerce application:
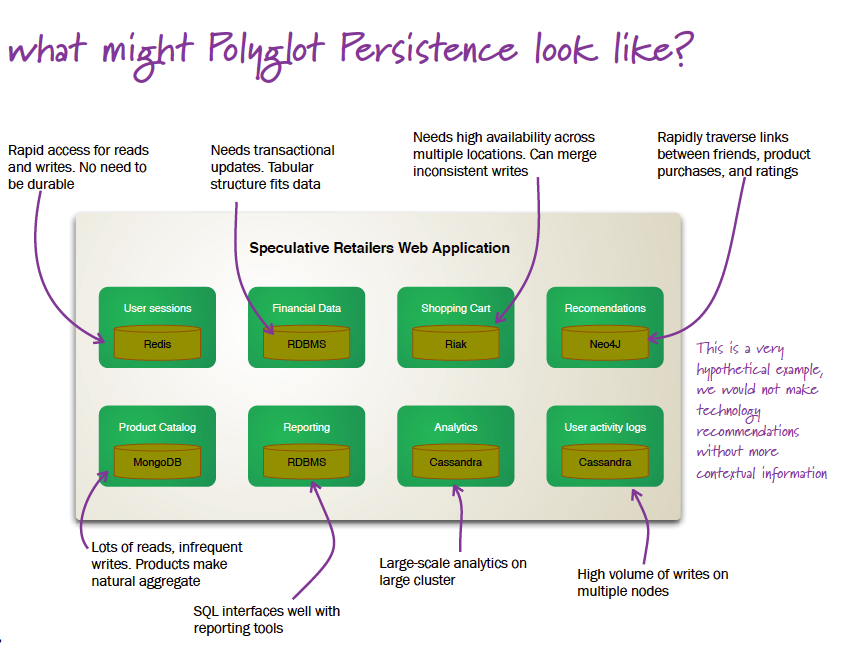
In this case, the application includes a Redis database for non-durable but rapid read / write access, an RDBMS for financial data, a Riak database for the shopping cart, with high availability and capability to merge inconsistent writes, a graph database (Neo4J) for recommendations, and so forth. As a general rule, SQL databases are effective in executing “Create, Read, Update and Delete” (CRUD) operations. For more complicated operations, some form of NoSQL database is probably required.
There are a variety of databases, each with unique capabilities. It may surprise you but a file system is actually a database. HDFS and ZFS are the rapidly emerging file system leaders. One example of a distributed SQL database is Microsoft’s new SQL server. Data warehouses are usually structured as SQL databases. Snowflake is a data warehouse technology that supports enterprises moving their warehouses onto the cloud. An example of an in memory distributed database that operates on the cloud is Redis. NoSQL databases are many in number, but Apache Cassandra, MongoDB and CouchDB are commonly used.
The fit systems enterprise exhibits polyglot persistence.
Database Types
If yours is a legacy enterprise built on technology from the eighties and nineties, your database solutions — like the applications they support — are probably monolithic. Back then, the only database type available for broad use was a relationship database management system (RDBMS) — most likely an Oracle database, Sybase database, IBM DB2, Microsoft SQL Server or something like that. The only type of data these systems could support was SQL-based data. These SQL data warehouses were purchased with licenses and managed on premises in private data centers or co-location facilities.
SQL-based data warehouses exhibit structured data. The data schema is rigid; it is schema on write. The schema is structured as simple tables, with columns and rows. SQL databases were appropriate for the needs that existed when they were built — straightforward operational processing and basic BI analysis of transactional data emerging from basic homegrown applications and vendor systems of record. With the rise of the Internet, open source versions of SQL emerged, such as MySQL and Postgres.
But as time went on, large Internet players such as Google and Amazon began to bump up against the limitations of SQL-based RDBMS databases. They needed more flexible data models, and a data infrastructure more aligned with agile methods and domain-based teams. Data volumes were now orders of magnitude greater than before. And the types of data were beginning to change. Data processing couldn’t wait for slow, single-purpose databases. New needs were emerging.
For the enterprise that has been around for more than twenty years, you still own a monolith. No matter how advanced you are, your monolith is probably not yet fully decomposed. It still needs to process transactional data — perhaps at much higher volumes than originally planned. Until recently, the only option was to scale vertically — to build bigger machines for processing. This is expensive and increases the operational burden. More recently, solutions such as Snowflake have emerged. With Snowflake, the enterprise can move its legacy SQL data warehouse to the cloud, gaining access to elastic horizontal scaling, cloud-level security and cloud-based compute cost models.
But back to the evolution of technology. Data volume, variety and velocity pressures led Amazon and Google to innovate. They were early leaders in developing what are now called NoSQL databases. NoSQL is a general term broadly meaning non-relational databases available via open source models that are cluster (i.e. cloud) friendly, schema-on-read and designed for the 21st Century web. The NoSQL term captures multiple types of databases, including:
Tabular
- Data is stored in rows and columns
- Users can query via column-based access
- Very high performance; highly scalable
- Examples: DataStax Enterprise (built on Apache Cassandra); HBase; Google Big Table
Key / Value
- Database is made up of data represented by a key (a unique identifier), and then a value (which can hold a lot of data within it and does not need to follow any structure)
- Offers more flexibility than tabular data
- Examples: Amazon DynamoDB, Riak, Oracle NoSQL
Document
- Document data also is represented by a key
- But the underlying data has some structure to it
- It is used to store, retrieve and manage document-oriented information
- It is often stored as JSON (a way to represent a specific piece of information in a NoSQL fashion)
- Examples: MongoDB, CouchDB
Tabular, Key / Value and Document databases are all aggregate oriented databases. Aggregate data is data that is collected from multiple sources and brought together in a hierarchical relationship with a summary. An example of aggregate data would be a purchase order, which might include the purchase of three of Product A and two of Product B. Another example would be a news article, which is comprised of many words but is organized under a summary headline.
The fourth type of NoSQL database is a Graph database. Graph databases are not aggregate oriented:
- Data is broken down to the most atomic level
- Relationships are mapped between data elements
- This is the only type of NoSQL database that follows ACID principles (Atomic, Consistent, Isolated and Durable)
- Is used to find commonalities and anomalies in large datasets
- Can handle hundreds of joins for advanced analytics
- Examples: DataStax Enterprise Graph; Neo4J
The Data Lake
In enterprise technical systems, the requirements of the application will govern whether the data needs to be fast or slow, structured or semi-structured, ephemeral or persisted. Services will operate and inter-operate as required to complete their assigned jobs. Each service will own the database it needs, resulting in polyglot persistence. All of that is well and good.
But to create a self-service data driven culture, you need ready access to all of the enterprise’s data. Ad hoc data analysis is a common activity in the fit systems enterprise. Since you can’t predict what data may prove valuable for future analytical needs, the data infrastructure must provide access to the widest possible array of data. For this purpose it is advisable to build a data lake, into which you pour all your data in its raw form. As services execute operations they feed data into the lake so that data scientists and other end users can conduct analysis.
In their book, Creating a Data-Driven Enterprise with DataOps, Ashish Thusoo (CEO of Qubole) and Joydeep Sen Sarma (CTO) provided a comparison of data warehouses and data lakes²:
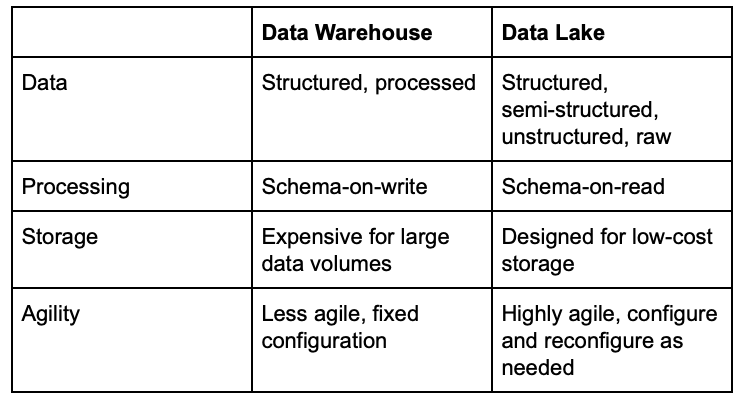
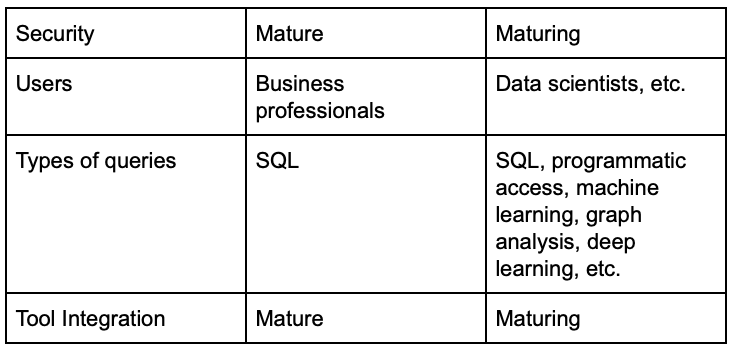
Today, most data lakes are not meant for operational data processing. They exist for analysis. The data in a lake is raw; it doesn’t need to follow any specific structure. Data residing in a data lake should be tagged with metadata that clarifies its provenance: what system it came from, and when it was produced. Data scientists and business users can then build queries, extract the data they need and then organize it as necessary. However, in the not too distant future data lake type databases will increasingly support real time operations, especially in the AI / ML / DL arena.
Data System Requirement #4: Ensure Efficient Accessing, Processing and Use of Data
To manage big data on the cloud, you need systems built via reactive microservices architecture. “Reactive” refers to the idea of asynchronous message passing between services. It is this attribute that enables a given service to be processed concurrently, enabling elastic use of compute power on the cloud. Concurrent processing enables a service to be resilient (it can self-heal), and responsive (high availability / low latency).
Message queues are key building blocks in the efficient accessing, processing and use of data. When two or more services need to communicate with each other, it’s important to avoid a direct HTTP call. That would make the services tightly coupled, which defeats a key attribute of reactive microservices architecture. The message queue achieves the necessary indirection to retain loose coupling between services. RabbitMQ and Kafka are examples of a message brokering system.
There are two modalities for processing data: Batch Processing and Streaming Processing. Frameworks such as MapReduce are often used to scale these processing methods.
Batch Processing
Data analysis jobs have historically been run as batch jobs. This allows the processing of large datasets, but has sometimes come at the cost of speed. In his book Fast Data Architectures for Streaming Applications, Dean Wampler shared a reference architecture for a batch-mode data processing engine:
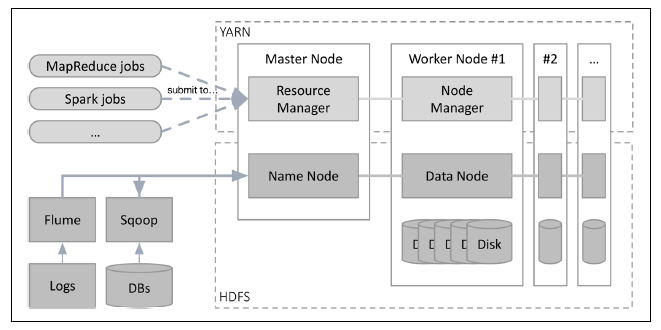
Here the subsystems are clusters spanning physical machines, denoted by the dashed rectangles. Data is ingested into the HDFS subsystem. The data could flow into SQL and NoSQL databases, HDFS, or a cloud object storage system such as AWS S3.
Analysis jobs can be written in Hadoop, Spark or Hive, and are broken down into tasks that are run on worker nodes as assigned by YARN.
Batch-mode systems can manage terabytes to petabytes of data, can process data in minutes to hours and can execute jobs in seconds to hours.
Streaming Processing
With interaction data, the volume, variety and velocity requirements are often greater than can be addressed in a batch-mode system. In fast streaming data applications, you may need results to be delivered into the running system with sub-second response times. For example, Amazon’s Lambda architecture has emerged to deal with this — with its speed layer for real-time online processing and a batch layer for comprehensive offline processing. But this requires two data models and data processing pipes, with a merge at the end. New pure stream processing architectures are emerging to deal with this problem. Processing is brought inside the service, with communications that leverage event logging. These can support both client-to-service and service-to-service communications.
For such requirements you need a fast data architecture. Wampler shows such a reference architecture below:
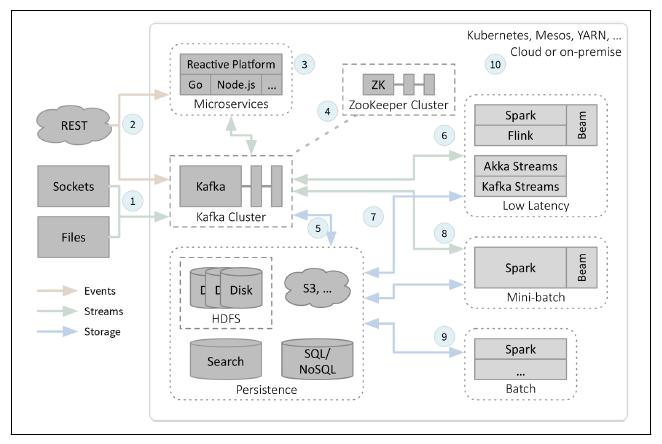
Here the data can come from a variety of sockets, APIs and files. Meanings of the numbers on the above graphic are below:
- Streams (high volume) come from sockets (such as telemetry feeds) and files (such as record logs).
- Events (which require data state changes, and are usually lower in volume) come from REST APIs.
- Microservices manage and monitor tasks such as streaming data state updates to and from Kafka — good for integrating time-sensitive analytics with other microservices
- Kafka is a stream-processing platform supporting high throughput at low latency. With Zookeeper it can execute consensus processes such as leader election and storage of some state information
- Kafka Connect allows raw data to be persisted, moving it to long-term storage. The data can move in both directions, so that it can feed downstream analytics with relevant data as required
- Low latency stream processing can be ingested into a stream processing engine such as Spark, Flink, Akka Streams or Kafka Streams
- The results of stream processing can be written to persistent storage, or data can be pulled from storage for processing
- One way to process streaming data is as a mini-batch — a method used by Spark Streaming
- This structure also supports batch-mode processing, meaning that you don’t need two separate infrastructures
- This data processing system can be deployed on the cloud, with cluster resources managed by technologies such as Hadoop/YARN, Kubernetes or Mesos
With fast data architecture, the data size per job can be megabytes to terabytes, the time between data arrival and processing can be microseconds to minutes, and the job execution times can be microseconds to minutes. Each streaming has a smaller capacity than in a batch-mode architecture, but the processing speed is orders of magnitude faster.
MapReduce
MapReduce is a programming pattern that enables you to concurrently process big data by splitting the data into smaller pieces and processing them in parallel (map). When complete, the data can be aggregated again and sent to the application as a consolidated output (reduce).
Here is a graphical representation of MapReduce steps:
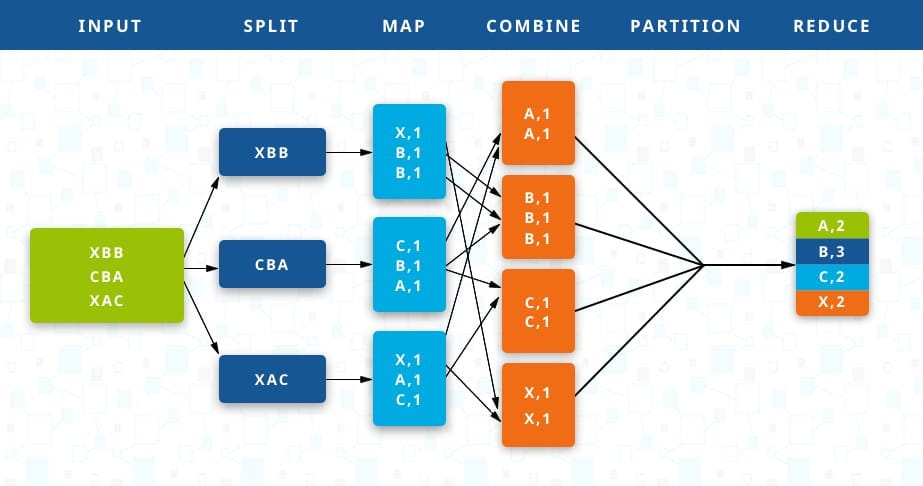
MapReduce is a core capability in modern big data infrastructure.
Data System Requirement #5: Ensure Efficient Use of Compute Resources
To make all this work efficiently, a set of core infrastructure technologies are required. This includes the cloud providers, the technologies that support distributed computing, distributed computing management systems and container and cluster management systems.
Cloud Providers
AWS, Microsoft Azure and Google Cloud are the primary contenders in the cloud space. All three providers have built up a growing array of platform tools and reference architectures companies can use to manage their data infrastructure.
Distributed Resource Management
YARN is a resource manager, managing the distribution of jobs to compute resources. It is associated with the Hadoop MapReduce API. Because of its genesis, YARN is best suited to Hadoop jobs.
Containers and Cluster Management
When it comes to container orchestration and cluster management, you need to be able to manage workloads across multiple servers in an efficient manner. This requires high availability, ease of deployment, ease of service discovery and fast networking. Technologies have emerged to do the job.
Compute clusters are a shared computing environment. They are made up of nodes, which process tasks and jobs. To manage a cluster you need a cluster management framework consisting of a resource manager, task manager and a scheduler. A variety of solutions exist in the container and cluster management space. Here are just two:
Docker Swarm
Using Docker Swarm, developers can build and ship multi-container distributed applications. The technology offers clustering, scheduling and integration capabilities. You can scale multiple hosts and leverage technologies such as Mesos for large-scale deployments. Docker Compose provides orchestration capability.
Kubernetes
Kubernetes is a container cluster manager. It is made up of pods, labels, replication controllers and services. Pods enable data sharing among tightly coupled components. They can tightly group containers and schedule them as a node. Labels are the metadata used to manage components. Replication controllers can create new pods as needed. And services route the requests to the right pods. Through services, databases can be externalized with a cluster. They keep track of components as clusters shrink and grow.
Data System Requirement #6: Ensure Capacity to Monitor Performance and Fix Problems
There is a growing array of platforms available to support modern cloud-based data infrastructure, including companies such as Cloudera, Delphix, Mesosphere, DataStax, Lightbend and Qubole. While each platform has a different purpose, all share in common the goal of reducing operational burdens, increasing security and improving monitoring. These companies are critical enablers of both the DataOps and Engineering Systems. I will share more about three of these platforms below.
The more you can abstract away operational details in your data infrastructure, the better. You want a system that can automatically spin up new clusters when needed, and retire them when workloads ease back down. It should be secure. It should be easy to monitor. For instance, say there is a workload that is hogging compute capacity. A good data platform would help your data team to detect the problem quickly and rewrite queries to improve performance. A good data platform frees your central data team from becoming a bottleneck. Data team time is best spent on solving business problems, not dealing with detailed wiring issues. In managing the data supply chain, any technology that can make the capture, ingestion, preparation, cleansing, analysis and egress of data more efficient is a good tool to have.
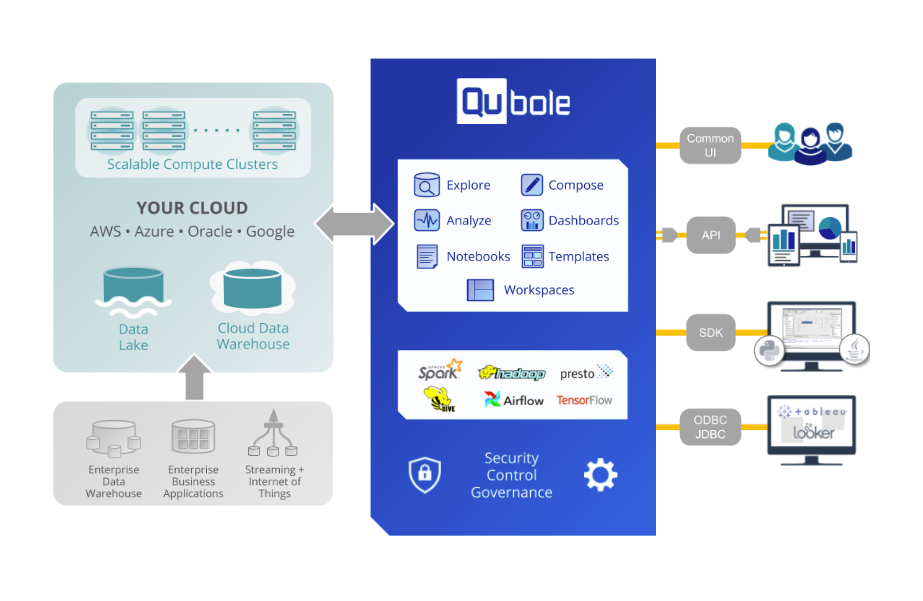
Qubole
An example of such a platform is Qubole. It is built to support the efficient, cloud-native analysis of big data workloads. It supports the analysis data in a data lake and in data warehouses. It is elastic, resilient and responsive.
Its architecture looks like this:
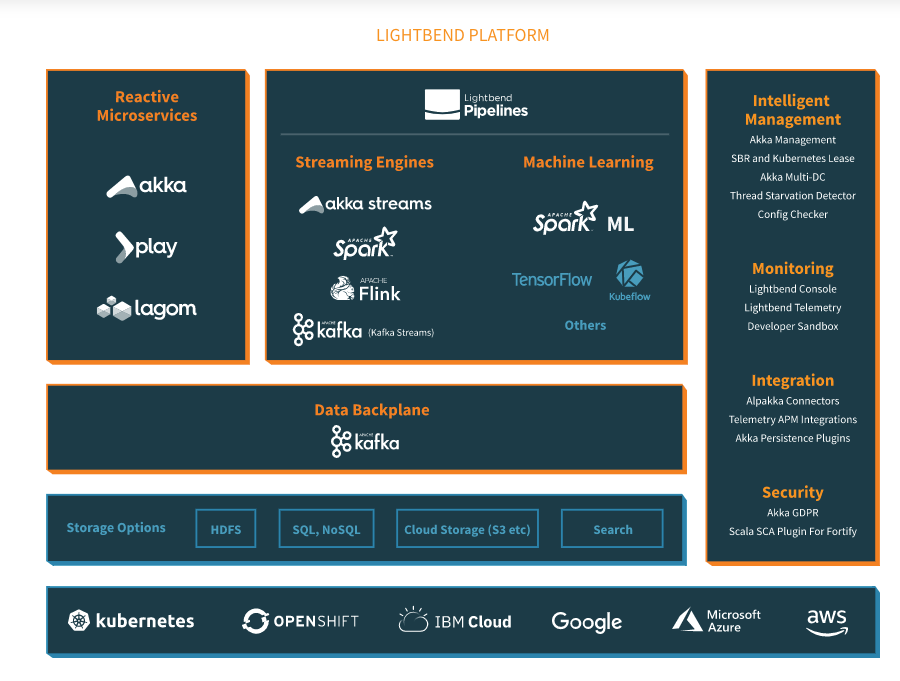
Lightbend
Lightbend is a different type of data platform. The purpose of Lightbend’s fast data platform is to build and run fast data systems. Developers can use the platform to build fast data applications much more efficiently. It then supports continuous integration, delivery and deployment in streaming environments. It also includes production tooling that delivers at-scale resilience and monitoring tools.
Here is the architecture of its fast data platform:
Delphix
The Delphix platform serves data operators and data consumers. For data operators, it delivers data security, virtualization, replication, monitoring and automation of tasks. Security is delivered via automated and custom masking so that data is compliant before being distributed. The platform virtualizes with compression, creating lightweight virtual copies that are continuously synced with source data. Replication enables data to be moved for cloud migration or backup. Many coordination and management tasks are automated, and the platform has robust monitoring capabilities.
For data consumers, the platform supports versioning, sharing, replicating, restoring, bookmarking, branching and refreshing.
Here is a view of the platform’s functionality:
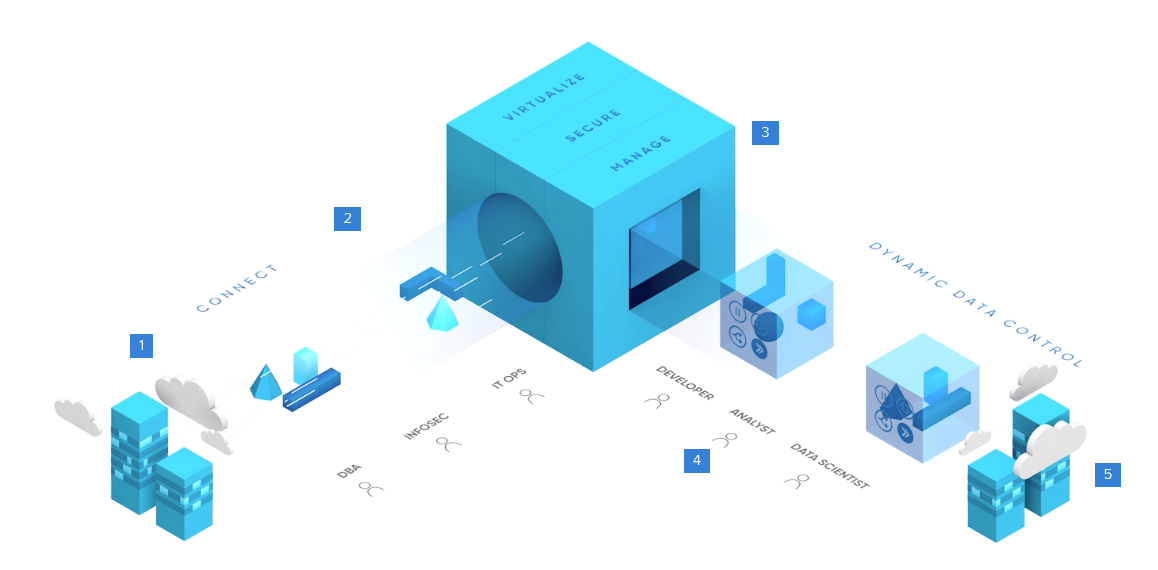
- Non-disruptively ingest data from on-premises or cloud environments
- Virtualize with compression to create lightweight virtual copies
- Secure the data based on governance policies
- Deliver self-service data pods to data consumers
- Bookmark, refresh, rewind, branch data within each data pod at will³
Summary
Data is everywhere. It sits at rest in a wide array of databases sprinkled throughout the enterprise. It’s in motion in operational transformations and analysis workloads. It can be transactional or interaction-based; structured or semi-structured. As data explodes in its volume, variety and velocity, the fit systems enterprise leverages data to gain powerful insights that power automated and human actions. The action may be automated, such as with deterministic or cognitive changes in a technical system. Or it may be human, such as when a diagnostic or prescriptive result mobilizes leaders to act. In the fit systems enterprise, rich feedback loops deliver a steady drumbeat of data to leaders. In The Loop leaders act on that data to advance the enterprise’s generative and adaptive imperatives.
Creating a mature, data driven culture requires a sophisticated data infrastructure. Specific technologies will evolve at a rapid rate and are likely to change over time. But the core principles underlying this chapter are likely to remain consistent. Data operations is a system. Like all business systems, its health depends on the quality of interactions between people, workflows, technology and money flows.
To view all chapters go here.
If you would like more CEO insights into scaling your revenue engine and building a high-growth tech company, please visit us at CEOQuest.com, and follow us on LinkedIn, Twitter, and YouTube.
Notes
- Damle, Ash. May 3, 2019.
- Thusoo, Ashish, and Joydeep Sen Sarma. Creating a Data-Driven Enterprise in Media. Sebastopol, CA: O’Reilly Media, Inc., 2018.
- “The Delphix Dynamic Data Platform.” Delphix, n.d. https://www.delphix.com/platform.