
DataOps is a meta system. The purpose of the DataOps system is to place the right data into the right hands (or systems) at the right time all the time. In a healthy DataOps system an enterprise-wide hunger for data is satisfied by rich, diverse feedback loops yielding data to teams and technical systems at the point of impact. Data-driven decision making is a hallmark of the fit systems enterprise.
In early stage companies, the DataOps system and Engineering system are commingled, managed by heads of Product and Engineering. For most companies, they start to separate at or around the Minimum Viable Expansion stage. However, in a company whose product is (by its nature) data intensive, the DataOps system matures faster into a separate system. Eventually, every successful enterprise needs a healthy, separate DataOps system.
The DataOps system makes accessible for analysis two types of data. The first is transactional data. This is the data embedded in systems of record, such as ERP, CRM and accounting platforms. Rented technical systems such as these are managed by Operations functions — FinanceOps, SalesOps, MarketingOps and so forth. Transactional data is usually stored in data warehouses such as Oracle and Teradata databases. Volume and variety are relatively low. Transaction data usually shows up in dashboards and KPIs.
The second type of data is interaction data. This includes sentiment data from social media, data with unique structure such as images and videos, the data from IoT sensors, event logs inside technical platforms, and product-generated data. Here, data is high volume, high variety and high velocity. If present in enough volume, this data can power AI. Interaction data may be stored within the service itself for ready use or persisted in a data lake to support future ad hoc analysis.
Data can be at rest — sitting in a database, waiting to be retrieved and analyzed. Or data can be in motion — for instance, streaming data or data in transformation. The DataOps system in the fit systems enterprise maintains a data infrastructure that can accommodate both.
There are six types of data transformation:
- Deterministic (a trigger initiates an automated cause-effect transformation inside a machine — such as adding to an event log or a call to a web page)
- Descriptive (business dashboards — KPIs)
- Diagnostic (ad hoc search, query tools such as Hadoop, Presto, Impala — exploring data to find intelligence; leads to statistical models and analysis reporting)
- Predictive (modeling, data science, machine learning — apply statistical techniques to train models that predict based on past behavior, using tools such as Apache Spark)
- Prescriptive (recommendations from machine learning, artificial intelligence, deep learning — enables you to derive increased structure out of loosely structured data — i.e. image recognition and natural language processing — using tools such as Google’s TensorFlow)
- Cognitive (acts automatically based on rules, leveraging machine learning, artificial intelligence, deep learning — such as is used in robotic process automation)
In the fit systems enterprise, the workflow impact of systems of record and internal platforms are clearly identified. The meaning of all data states are clear and universally understood. Metadata protocols are consistent across the enterprise, enabling intersystem analysis based on one source of truth for each bounded context. Permissions and authentication are carefully managed. Within the constraints of legitimate permission thresholds, the bias is to democratize data access. Infrastructure has been built to support a self-service, data driven culture.
The DataOps system may or may not include a centralized data team. If it does, the focus is not to be a data gatekeeper. The team’s role is to ensure the tools and infrastructure are in place to enable self-service. Regardless of how it is organized, the DataOps system impacts the following roles:
- Architects
- Developers
- Data / ETL engineers
- Data scientists
- Data analysts
- Business users (such as Sales Ops, Marketing Ops and Finance Ops)
- Top executives
As a meta system, the DataOps system’s role is to increase the capacity of teams within the operating systems to self-organize. Because it maintains centralized oversight over data state definitions and metadata protocols, and controls the development of data infrastructure, and manages permission rules and curated datasets, the DataOps system enables autonomy at the nodes — in the same way that central management of a highway system enables the cars and trucks to go where they need to go.
Data-driven insight is key to balancing alignment with autonomy. Data enables leaders to track the progress of self-organized teams. But to make it all work, the DataOps system must ensure enterprise-wide commitment to:
- Creating and sustaining a data-driven culture
- Agreed enterprise-level data state definitions
- Agreed data schemas
- Common metadata protocols
- Clear data supply chain infrastructure
- Clear permission rules
- Coordination of data protocols across the enterprise
Let’s go through each. A number of these topics will be addressed in greater detail in Chapter 25 — Managing Big Data on the Cloud.
Requirement #1: Creating and Sustaining a Data Driven Culture
As CEO, it’s your job to strengthen the health and maturity of your operating systems. Strategy is shaped by your generative and adaptive imperatives. It points to a prioritized list of projects and initiatives. To ensure progress, you need data. Data is the raw material of knowledge. When transformed into analysis, it is your evidence of progress and problems. As such it is fuel for decisions.
But in the fit systems enterprise, data isn’t just for leaders. Self-organized domain teams need to understand their own performance and stay aligned with enterprise purpose. That’s why it’s so important for data and analysis to be democratized.
Achieving democratized access to data and analysis is a technical challenge. More about that later in the chapter. But it is also a cultural challenge. A data-driven culture doesn’t just happen. It starts with leaders who are systems thinkers — who understand that every operating system in the enterprise exhibits dynamic complexity. People, workflows, technology and money flows interact in complex ways, and cause and effect may be separated in time and space. Data is the means by which performance is tracked and links between cause and effect are exposed.
For you, the CEO, it starts with a data-first mindset. This will lead you to design your operating systems in such a way that the status of stocks and flows are clarified. Each stock is a data state. For every data state there is an event log to record the data.
A data-first mindset changes your expectations of executives. In decision making, opinion is fine — but executives can be prone to leaps of abstraction. It’s all too easy for a manager’s ad hoc observation to lead to a sweeping generalization. But when you expect data-driven decision making, you change the executive game. It’s no longer enough to bring opinion. The successful leader must bring data. In a data-driven culture, the frontline employee armed with superior data has more power than someone with superior positional power who merely holds an opinion.
Your expectation of data-driven decision making must reach across the enterprise. Every small, self-organized, cross-functional team needs SMART (specific, measurable, actionable, results-based and time-bound) goals. They need access to the data necessary to track their progress and inform their continuous improvement decisions.
As a company shifts towards a more data-driven culture, it will pass through five stages of maturity (the following maturity framework closely follows the framework presented by Ashish Thusoo and Joydeep Sen Sarma in their 2017 book Creating a Data-Driven Enterprise with DataOps¹):
1. Not data driven, but aspire to it
- The CEO and top team recognize the need for data in decision making
- They observe the gaps in culture and infrastructure
- Search begins to understand cultural and technical requirements
2. Initial infrastructure work; experiments underway
- Systems of record and data states defined
- KPI dashboards developed
- Some teams pursue ad hoc queries through central data team
- The number of analysts in the company grows
3. Expansion underway; expectations rising
- Metadata protocols established
- Data supply chain infrastructure advances
- Business intelligence tools reach deeper into the organization
- Ad hoc query tools introduced; access to tools expands beyond central data team
- The number of analysts continues to grow; the first data scientists arrive
- Statistical skills rise throughout the company
- A rise in expectations for data driven decision making at all levels
4. Inversion
- The demand for data and analysis begins to rise rapidly
- Infrastructure struggles to keep up with rising demand
- Self-organized teams operate with a data-first mentality
- Analysts exist in teams throughout the company
- Data scientists are in place wherever advanced modeling and analysis make sense
- Compute costs and system constraints cause need for resource sharing rules
5. Ubiquity in data driven decision making
- Infrastructure is mature
- Permissions architecture is mature
- Access is increasingly user-friendly
- Data is central to decision making
- The level of statistical skill is high throughout the company
- Data is being leveraged across the analysis continuum from KPIs to machine learning
As you embark on creating a data-driven culture, you will face resistance. The greatest resistance may well arise at the top, as people holding positional power realize that decision authority has begun to flow to people holding data power. Leaders must become comfortable with being challenged by data on everything from strategy to plans to daily decisions. Data flattens hierarchies.
Requirement #2: Data State Definitions
To understand the status of things, everyone needs to agree on the meaning of data states.
Definitions must be rigorous and universally applied. For example, if a “Marketing Qualified Lead” (MQL) means “raw lead” to the marketing department and “vetted, qualified lead” to the sales department, conflict is certain. When is a customer “active”? Is it when the customer signs a contract? Is it when a customer has launched? Do you consider a customer on “pause” an active customer? Is a customer that is delinquent in paying its bill an active customer? Is a customer that has submitted a cancellation request but is still live an active customer?
Definitions matter. For data states that are relevant within just one domain or system, the meaning of the data state can be defined by the occupants of the domain or the system. But for data states that are significant to multiple systems within the enterprise or multiple levels of the organization hierarchy, everyone needs to agree on the same definition.
To determine a data state definition, you start by defining the workflow of interest and the system of record that supports the workflow. Every step in the workflow is a data state. You then bring together stakeholders to agree on definitions. This includes defining the required transformations to move from one data state to the next.
Requirement #3: Data Schemas
Records are often compiled from data residing in multiple systems. For instance, the customer record may draw upon fielded data in the product platform, CRM system and accounting system. In order to organize this information, data hierarchy rules must be written. How do you define “customer”? Is the customer General Electric, or is it the Marketing Department in the San Francisco Region of General Electric? This is a data schema rule. Schema rules define the hierarchical relationship between fields, records, files and databases, and the relationships between data objects. The hourly pay rate is a field. The employee is a record. The employee’s department is a file. All department files are maintained in a database. The employee may be a member of a cross-functional team, and may be responsible for a given set of customers. These hierarchical and non-hierarchical relationships are parts of the “employee” data schema.
The DataOps system’s job is to ensure data schema rules are applied consistently. If the customer database were to show five separate customers, each representing Microsoft divisions that hold a separate contract, and then also show one customer record for all of General Electric (despite there being thirteen different active contracts tied to that company), that would be a problem. Customer analysis data (number of active customers, retention rate, etc.) would be polluted. So the DataOps system works to ensure that data schema rules are in alignment with the enterprise purpose and are applied consistently.
Requirement #4: Metadata Protocols
Metadata is data that describes data. For any data object, its metadata will identify what it means, who owns it, what it contains, when it was published, how it relates to other datasets, how it is organized, its key, how it is sorted, when it was created, when it was modified, when it was archived, who has access to it and how large it is. Data schemas are subsets of metadata.
Effective metadata management requires enough centralized control to ensure standard methods apply across the enterprise’s datasets. But wherever domain-specific knowledge and capabilities are required, crowdsourced metadata management (such as by a wiki approach) may be needed. Regardless of where you land on the control / crowdsourcing continuum, the key is for metadata to be appended and structured in such a way that data of all types can be retrieved and analyzed when needed.
Data curation is the management of data through its lifecycle. It involves implementing data schemas and metadata within a dataset. A data curator will determine which aspects of the dataset are most relevant, and will ensure these aspects are searchable and retrievable. Certain datasets have enterprise-level importance, which is why senior data analysts on the central team curate them.
Requirement #5: Data Supply Chain Infrastructure
The infrastructure requirements to support a data-driven culture have grown significantly. With the rise of interaction data and its explosion in volume, variety and velocity, enterprises have been challenged to build technical systems capable of supporting broad data access while maintaining proper security. As the technical challenge has grown, the analytical demands have risen — moving from descriptive to predictive to prescriptive to cognitive. The computational load has risen accordingly, as has the complexity for the humans that run the system.
The data supply chain is comprised of stages:
- Capture
- Ingestion
- Preparation and cleansing
- Analysis
- Egress
In the capture stage, data is collected at the source. These data sources may include extractions from vendor systems of record, event logs inside home-grown technology, or data streaming in from social media or IoT devices.
During the ingestion stage, data is imported from the source, transferred, loaded and processed for use or persisted to database storage.
In the preparation and cleansing phase, raw data is modified so that it fits into its assigned data repository and is retrievable. The job here is to solve the “garbage in, garbage out” problem. Through this process, unstructured data becomes structured. This involves normalizing, de-duping, updating and often anonymizing data. Historically, this has been the most cumbersome step in the data supply chain.
In the analysis stage, data is modeled so as to discover new insights and inform decision making or drive actions.
In the egress stage, users are presented structured data such as KPIs and provided tools for ad hoc queries.
Data use and analysis context has an impact on infrastructure. If you need strong data consistency, you will face some latency in rendering the query result. That is because there is a lag in the receipt and processing of data. For instance, if you need to know the number of customers who executed transactions on the last day of the month, you may need minutes, hours or even days to complete all the processing of transactions required in that calculation. On the other hand, if eventual consistency is sufficient, you can reduce the latency of rendering a result. This happens with your hotel charge. If your bill you are handed at checkout didn’t account for the beer you took just before you left your room, the hotel will reissue the bill and send it to you via email, after having charged your credit card accordingly. The first paper invoice was “roughly right” — slightly inaccurate, but close — and updated later. In data infrastructure design you will often face a choice: strong consistency with high latency, or eventual consistency with low latency.
To process high volumes of data you need three components:
- A scalable storage solution, such as a database or distributed file system
- A distributed compute engine, for processing and querying the data at scale
- Tools to manage the resources and services used to implement these systems
As your data-driven culture matures, more demands will be placed on your data supply chain infrastructure. You will set rules for resource access. You will harden your infrastructure by implementing braking mechanisms, such as an upper limit on the amount of data queried and filters on data transformation. You will tune the system to automatically shut down if a query begins to run out of control.
Security will of course be a key concern. Each API call needs to be authenticated and authorized consistent with your permission rules. You will need to address data encryption, user management, identity and access management, and data residency. Major cloud providers have their own security capabilities, to ensure they are compliant with ISO 27001, HIPAA, FedRAMP, SOC 1, SOC 2, etc. More about this in Chapter 29 — Trust.
Requirement #6: Permission Rules
While the bias is towards pushing data to the nodes, it’s important to secure sensitive data — such as data on personnel and customers and financial data. Permissions architecture still matters. In a data-driven culture, permission rules should operate on the opt-out principle: an employee should have access to the data unless there is an overt reason to opt the employee out of access. To execute permission rules, you need to authenticate, authorize and audit. More about permissions in Chapter 29 — Trust.
Requirement #7: Coordination of Data Protocols Across the Enterprise
The creation of a data-driven culture requires every stakeholder in the data supply chain to get on the same page. This includes the producers of data, the model-builders, the analysts, those responsible for protecting data, those responsible for setting permissions, and all employees who need the data and analysis to make better decisions. This is best achieved through a hub and spoke model, like this:
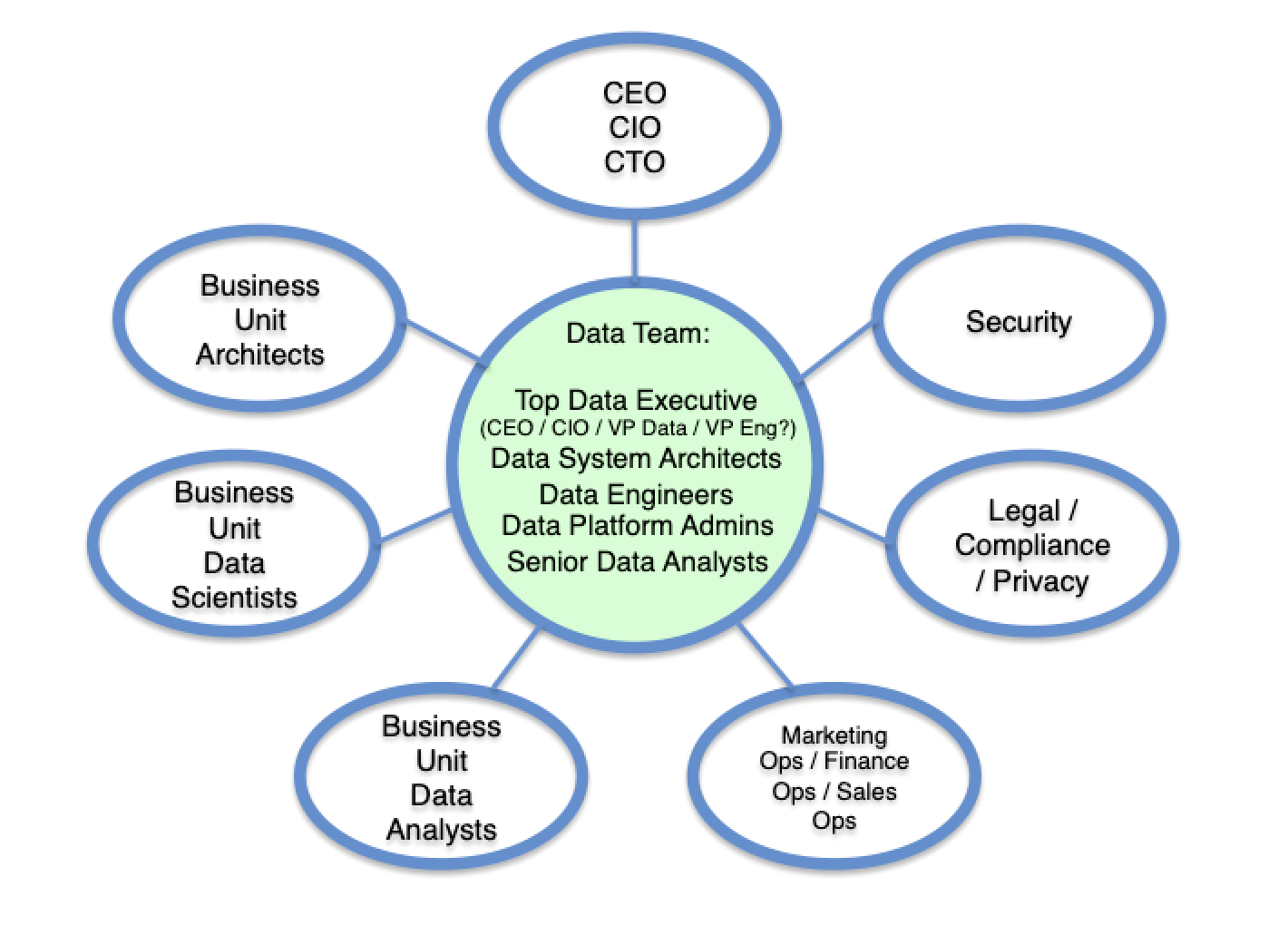
In this structure, there is a central data teamand an extended DataOps council. The presence of a central data team is not, in itself, evidence of a data driven culture. The evidence is in what the team does. In the fit systems enterprise, the data team’s purpose is to democratize data access, within the necessary constraints of confidentiality and privacy. The bias is towards access, not control. If you have an existing data team and you face resistance in widening data access, work hard to help data team members shift their mental models. Help team members understand that their work to democratize access makes them heroes. The data team will remain a vital component in the data-driven enterprise, and as dependency on data rises it will be fully employed doing important work. It’s the nature of the work that changes.
Here is the central data team:
Data System Architects architect the data infrastructure. Their job is to ensure it is constructed to support a self-service data capability throughout the enterprise.
Data Engineers put in place the mechanisms to capture source data throughout the enterprise, conducting ETL (extract, transform and load) actions. They normalize, cleanse and apply metadata to data objects.
Data Platform Administrators manage the data supply chain infrastructure. They maintain the DBMSs, data warehouses and infrastructure for processing big data and streaming data. They work to ensure adequate compute capacity for the demand, low latency and failover efficiency. Their job is to provide a high level of availability and access, while efficiently managing the cost of infrastructure. They also administer data access privileges and implement security and control policies.
Senior Data Analysts curate the important enterprise datasets and conduct enterprise-wide data analysis. They prepare datasets with the right schemas and metadata, and turn business questions into queries.
The central data team is led by someone charged with the mission of building a data-driven enterprise. As a company scales a separate role emerges — such as VP Data or Chief Data Officer.
Surrounding the data team are the key stakeholders. These stakeholders may be represented on DataOps Council, which might meet as frequently as once a week to coordinate enterprise data protocols. The job of the data team and the DataOps Council is to get in place the data infrastructure, data state definitions, data schema definitions, metadata protocols and data management practices that enable democratized data access to occur.
Key stakeholders who may be represented on the DataOps Council are listed below.
Business Unit Architects design software. They create systems with inputs, transformations and outputs with event logs, message queues and changes in data states. All of these features of systems involve data at the core. As such, business unit architects are key stakeholders in the DataOps system. They impact data schemas, metadata protocols and access to data sources.
Business Unit Data Scientists are skilled in mathematics and statistics. They are capable of building and training machine learning models, deep learning and AI. They leverage tools such as Scala, Python and R to conduct predictive, prescriptive and cognitive analytics.
Business Unit Analysts are on teams throughout the company. Technical domain teams often feature an analyst. These analysts depend on self-service data tools. They turn business questions into queries, and produce analyses and reports for their teams.
DevOps, SalesOps, MarketingOps, FinanceOps, HROps and OtherOps Managers maintain systems of record (Marketo, Salesforce, NetSuite, ADP, etc.) within their respective function or system organizations. In the configuration and implementation of these systems, Ops managers define data states, charts of accounts, record structures and workflows. As such, they impact the data schemas and data states of the enterprise. All too often, systems such as these don’t interoperate well together. In the fit systems enterprise, the Operations Council works to streamline data infrastructure and coordinate data flows.
The top Security executive is responsible for ensuring technical infrastructure is protected from unauthorized access. This role spans the engineering and DataOps systems.
The Legal, Compliance and Privacy role may be held by in-house counsel or by external legal counsel. In some companies it is managed by the head of Finance. This person’s job is to make sure an appropriate permissions architecture has been constructed to address customer data privacy, HIPPAA and other compliance requirements, and that this architecture is being effectively executed via sound authentication protocols.
The DataOps Council is an example of an affiliation group. It is loosely coupled, but works to be tightly aligned. Business unit analysts report into their business units; Ops managers report into their functions; the head of security and the head of legal /compliance / privacy reports into the CEO or another top executive. They are joined together in their shared responsibility to create and maintain a healthy DataOps system.
Summary
A healthy DataOps system delivers leverage to the fit systems enterprise. If you can achieve level-five maturity as a data-driven company, you will have achieved powerful competitive advantage. But it takes time and dedication to get there. As CEO, it’s on you to maintain constancy of purpose. You will need to overcome resistance; many will resist the democratization of data. Everyone from senior executives to central data team members to employees throughout the company must buy in to the notion of democratized data access and adopt a data-first approach to decision making. To maintain it all, diverse stakeholders will need to work together. They will need to balance security and privacy with democratized access, biasing towards the latter without undermining the former.
Creating the data-driven enterprise takes work — but the payoff is profound.
If you liked this article and want to read others, click here.
If you would like more CEO insights into scaling your revenue engine and building a high-growth tech company, please visit us at CEOQuest.com, and follow us on LinkedIn, Twitter, and YouTube.
Notes
- Thusoo, Ashish and Sen Sarma, Joydeep. Creating a Data-Driven Enterprise with DataOps. O’Reilly Media Inc, 2017.
One Reply to “In The Loop-Chapter 16: The DataOps System”